 js正则表达式深度解析
js正则表达式深度解析
# 正则简介和图形化工具使用
正则表达式是一套匹配固定格式字符串的语法规则。常用来对字符串的查找替换等操作。 为了方便学习和使用正则表达式,可以借助图形化工具翻译 如网站regexper (opens new window)可以将表达式转换为图形语义
var reg = /\w{3,8}@(\w|\d){2,5}\.(\w){2}/
如下图展示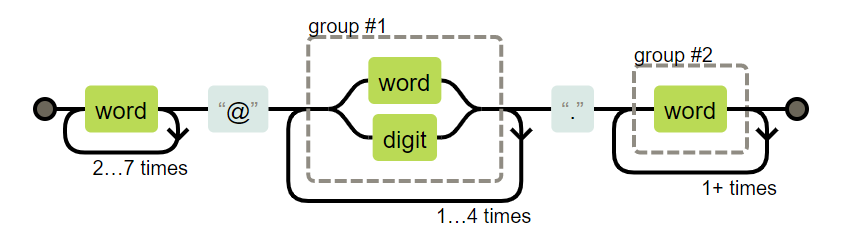 正则表达式可以通过对象字面量创建:
正则表达式可以通过对象字面量创建:
var reg = /\d+/;
也可以使用构造函数创建
var reg = new RegExp('\\bhello\\b','g');
正则表达式只有一个test方法,即(正则).test(字符串),其他的为字符串方法如(字符串).match(正则),(字符串).search(正则),(字符串).replace(正则),(字符串).split(正则)
# 修饰符
- g: global全局搜索,不添加的话,只搜索到第一个就会停止
'上海市北京市郑州市'.match(/市/,"省")
// ["市", index: 2, input: "上海市北京市郑州市", groups: undefined]
'上海市北京市郑州市'.match(/市/g,"省")
// ["市", "市", "市"]
2
3
4
- i: ignore case 忽略大小写,默认是大小写敏感
'heLlo worLd'.replace(/l/g,"!")
"heL!o worLd"
'heLlo worLd'.replace(/l/gi,"!")
"he!!o wor!d"
2
3
4
- m:multiple line多行搜索
"@123
@456
@789".replace(/^@./g,"!")
"!23
@456
@789"
"@123
@456
@789".replace(/^@./gm,"!")
"!23
!56
!89"
2
3
4
5
6
7
8
9
10
11
12
13
# 元字符
正则表达是有两种基本字符类型组成
原义文本字符:如“是”,“s”
元字符:在正则表达式中有特殊含义的非字母字符 ^ | $ ? * + . \ ( ) { } [ ] |名称|含义| |:---|:--😐 | ^ | 匹配输入字符串的开始位置。如果是在[]内,表示否定的意思 | | $ | 匹配字符串结束的位置。 | | . | 匹配除换行符(\n、\r)之外的任何单个字符。 | | \ | 将下一个字符标记为一个特殊字符的引用转义符。 | | * | 匹配显示零次或多次 | | + | 匹配显示1次或多次 | | ? | 匹配显示0次或1次 | | \b | 匹配一个单词边界,也就是指单词和空格间的位置。 | | \B | 匹配非单词边界。 | | \d | 匹配一个数字字符。 | | \D |匹配一个非数字字符。 | | \n |匹配一个换行符。 | | \r | 匹配一个回车符 | | \s | 匹配任何空白字符,包括空格、制表符、换页符等等。 | | \S | 匹配任何非空白字符。 | | \w | 匹配字母、数字、下划线。 | | \W | 匹配非字母、数字、下划线。 |
\b 匹配边界值

"hello world lo".replace(/lo\b/g,"!") > "hel! world !"
"hello world lo".replace(/\Blo\b/g,"!") > "hel! world lo"
\w 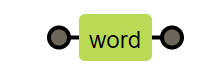 \d
\d 
# 字符类
一般情况下正则字符匹配的是一个字符串。如果匹配一类特性的字符,要创建一个特定的字符类,元字符[]可以把一些字符归为一类,表达式可以匹配这一类的字符。
如果使用/[hello]/,匹配到单独的或h、或e、或l、或o单个字母 /hello/匹配到完整的hello单词
/[hello]/
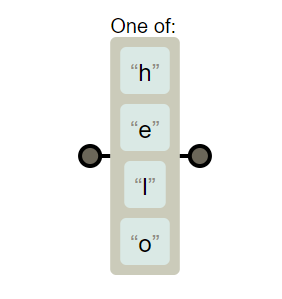 /hello/
/hello/

在字符类里面写上^表示否定
[^hello]
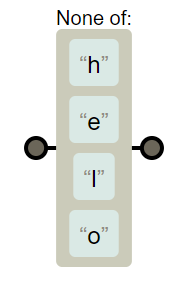
# 量词
{20}匹配20次 {4,}至少4次 {1,5}1次到5次 {0,8} 0次到8次 ? 零次或一次,最多一次 +一次或多次,至少一次 *零次或者多次
# 分组
可以使用()对要匹配的内容进行分组
"a1a2a3a4".replace(/\w\d{3}/g,"X")
// 匹配不到结果 "a1a2a3a4"
"a1a2a3a4".replace(/(\w\d){3}/g,"X")
//可以匹配字母加数字的重复3次 "Xa4"
2
3
4
分组常用于改变数据格式,反向引用 $代表分组的内容,$1表示第一组,$2表示第二组
"2019-08-06".replace(/(\d{4})-(\d{2})-(\d{2})/g,"$2/$3/$1")
// "08/06/2019"
2
# 范围类
正则表达式里有创建字符类,可以用来匹配一类字符,如[0123456789],这样会造成书写困难不雅观。可以直接写成[0-9],字母可以写成[a-z]。这是一个闭区间,包含了两头的字符。
"2019-05-01".replace(/[0-9]/g,"x") => "xxxx-xx-xx"
"2019-05-01".replace(/[0-9-]/g,"x") => "xxxxxxxxxx"
2
# 贪婪模式和非贪婪模式
正则表达式会尽可能多的匹配,默认贪婪模式
"1234567".replace(/\d{3,5}/g,"X")
// "X67"
2
将贪婪模式转为非贪婪模式,只需要在量词后加?
"1234567".replace(/\d{3,5}?/g,"X")
// "XX7"
2
# 前瞻
正则表达式从文本左边往右边匹配解析,向右边的方向称作“前” 从右往左匹配称作“后” 正向前瞻 exp(?=assert) 当符合了第一个表达式后,继续向右查看是否符合断言部分(也是正则表达式),符合了则为匹配 负向前瞻 exp(?!assert) 当符合了第一个表达式后,继续向右查看是否符合断言部分(也是正则表达式),不符合断言,则为匹配
断言部分不参与替换
"123wfor!dword789".replace(/\d{3}(?!(w))/g,"N")
// "123wfor!dwordN" 匹配到789并替换成N,因为123后面是w,不符合断言部分的后边不是w条件
"123wfor!dword789".replace(/\d{3}(?!(f))/g,"N")
// "Nwfor!dwordN" 匹配到123和789,断言是后边不能是f,都符合条件
"123wfor!dword789".replace(/\d{3}((?!(for)).)*$/g,"N")
//"123wfor!dwordN" 匹配到了789,因为123后边包含了for单词
// (assert.)*$表示以任意字符结尾往左查找,来判断断言部分的内容
// ((?!word).)*$ 表示字符串中不能包含word的断言
"123wfor!dword789".replace(/\d{3}((?!(word)).)*$/g,"N")
//"123wfor!dwordN"
2
3
4
5
6
7
8
9
10
11